¡Hola! I'm Shaizeen Aga.
I am a Technical Lead and Principal Member of Technical Staff at AMD Research where I lead a team of fantastic researchers focused on application-driven processor architecture design. More generally, my research interests include processor architectures, memory subsystems and security with a specific interest in architectures for Machine Learning and near-memory accelerators.
I received my M.S. (2013) and Ph.D. (2017) from the University of Michigan, Ann Arbor where I worked on several exciting topics including in-place computing in processor caches, building secure architectures at low cost, realizing intuitive memory models efficiently and improving performance of multi-core runtimes.
My work has been published at several top-tier computer architecture venues (ISCA, MICRO, HPCA, ASPLOS) and also at high-performance computing venues (SC). My research has won several awards
at and across institutional level and I was an invited participant in Rising Stars in EECS, 2017 workshop. I am also a (co-)inventor on over fifty (granted and pending) US patent applications.
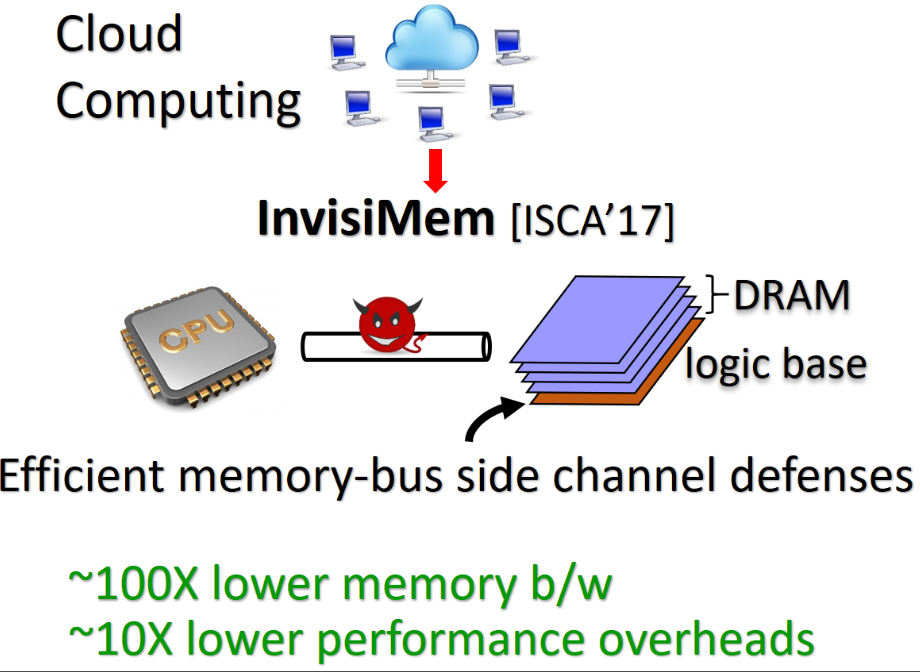 Problem context: Ensuring privacy of code and data while executing software on a computer physically owned and maintained by an untrusted party is an open challenge.
Problem context: Ensuring privacy of code and data while executing software on a computer physically owned and maintained by an untrusted party is an open challenge. 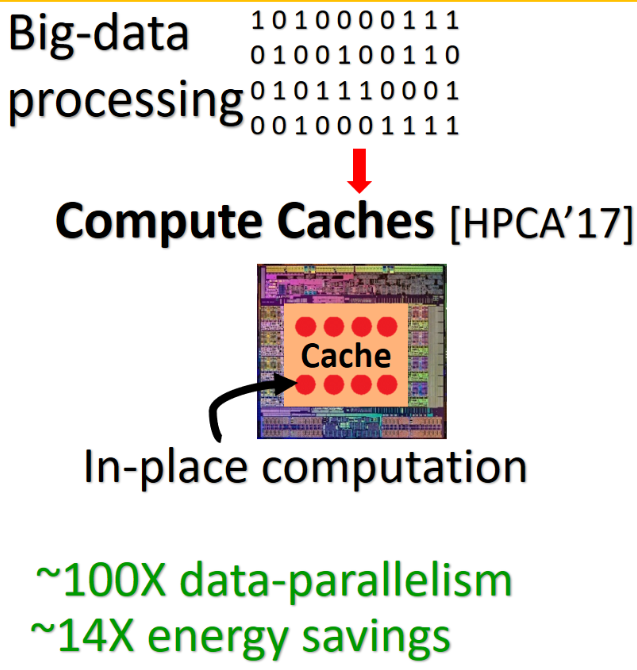 Problem context: We continue to generate nearly 2.5 quintillion bytes per day and as such, the amounts of data that needs analyzing will only increase with time.
Problem context: We continue to generate nearly 2.5 quintillion bytes per day and as such, the amounts of data that needs analyzing will only increase with time. 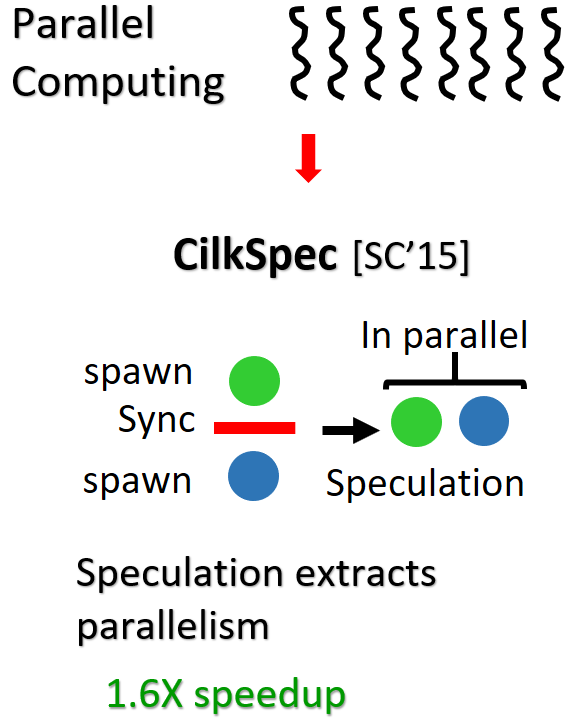 This project was part of my Internship with High Performance Computing group at
This project was part of my Internship with High Performance Computing group at 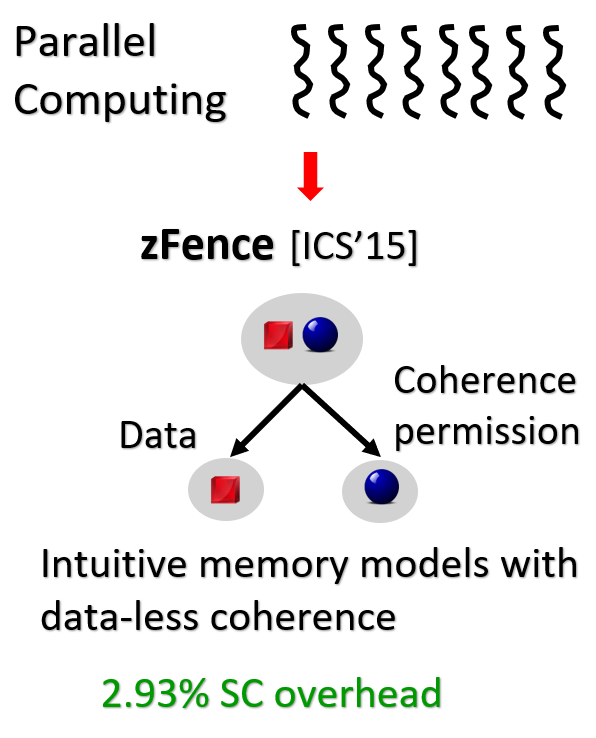 Problem context: With ubiquity of multi-core systems, a crucial debate is picking the memory model for such systems. Memory model decides the assumptions a programmer can make and
hence the ease of programmability.
Problem context: With ubiquity of multi-core systems, a crucial debate is picking the memory model for such systems. Memory model decides the assumptions a programmer can make and
hence the ease of programmability. 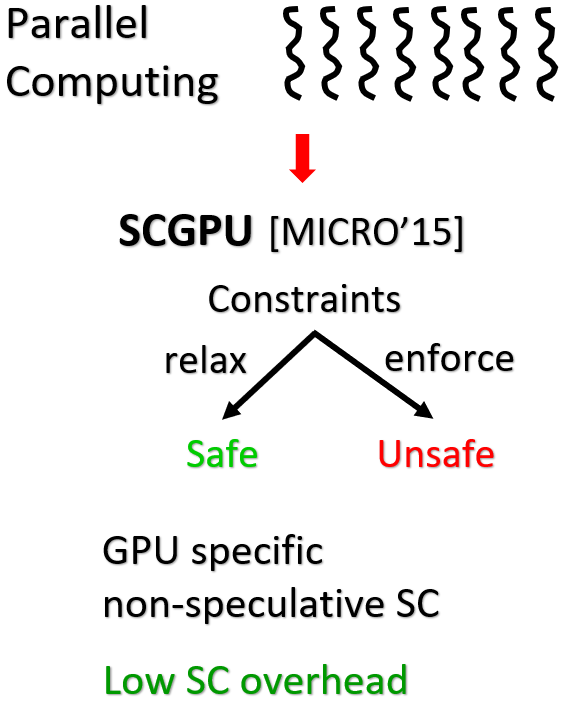 Problem statement: Picking an intuitive memory model is an important question for GPUs for they are now widely
used to write general purpose parallel programs.
Problem statement: Inspite of its simplicity, manufacturers do not implement Sequential consistency (SC)
and instead chose to support relaxed models which allow more performance optimizations.
Solution: In this work, I collaborated with fellow graduate student Abhayendra Singh to investigate memory model
implications for GPU’s wherein we propose a GPU-specific non-speculative SC design that takes advantage of high spatial
locality and temporally private data in GPU applications to bring down SC overhead.
Result impact: Our GPU-specific SC design shows that SC can also be enabled for GPUs for a minimal overhead.
Problem statement: Picking an intuitive memory model is an important question for GPUs for they are now widely
used to write general purpose parallel programs.
Problem statement: Inspite of its simplicity, manufacturers do not implement Sequential consistency (SC)
and instead chose to support relaxed models which allow more performance optimizations.
Solution: In this work, I collaborated with fellow graduate student Abhayendra Singh to investigate memory model
implications for GPU’s wherein we propose a GPU-specific non-speculative SC design that takes advantage of high spatial
locality and temporally private data in GPU applications to bring down SC overhead.
Result impact: Our GPU-specific SC design shows that SC can also be enabled for GPUs for a minimal overhead.